
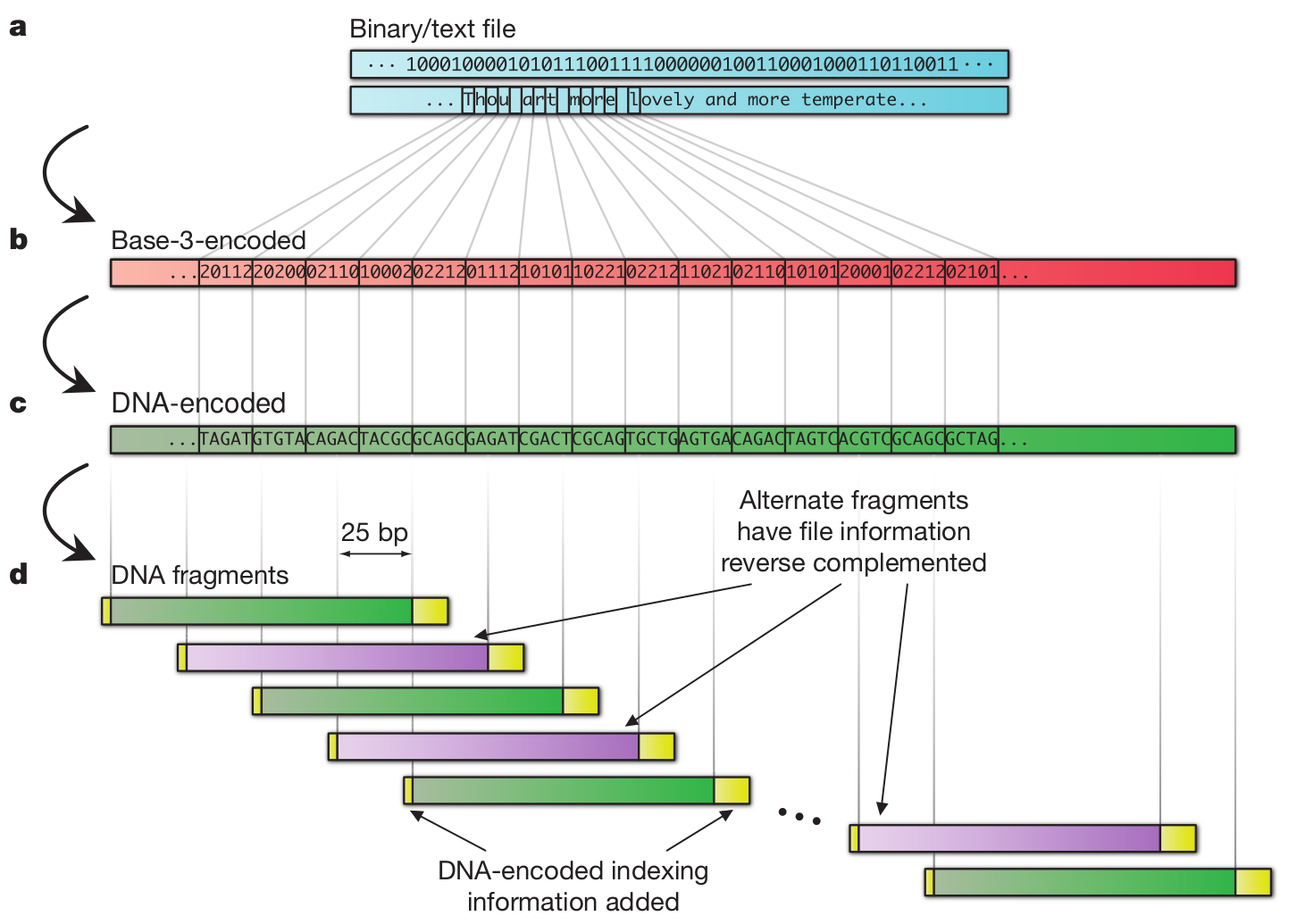
 Azt már szinte közhely, hogy egy DNS molekula alkalmas lenne hosszú távú adattárolásra, hiszen kis helyet foglal és bizonyítottan eláll évezredekig, miközben nem igényel különleges körülményeket. Viszont hátrányai is vannak, például a hosszú, adott szekvenciájú DNS szakaszok szintézise nem megoldott, azaz sehol sem tudnak neked tetszőleges bázissorrendű, egy gigabázis méretű DNS szálat készíteni. Ráadásul a bázissorrend meghatározása nem egyszerű és nem is gyors, de hát ez nyilván nem túl fontos szempont, ha évezredeken át meg akarunk őrizni valamilyen adatot. Nick Goldman és munkatársai (van köztük egy magyar is, Sipos Botond) éppen ezért kicsit másképpen közelítették meg a dolgot: Ismert bázissorrendű rövid DNS szakaszok könnyen és viszonylag olcsón szintetizálhatóak, így eleve ezeket használták föl adattárolásra. A 757 kilobytenyi kiválasztott adatot egy egyszerű kódtábla alapján DNS szekvenciává fordították, amely így nem tartalmazott ismétlődő bázisokat, mivel ezeknél gyakrabban lépnek fel hibák a második generációs szekvenálási eljárások során, így több hibával lennének csak kinyerhetőek az adatok. A csak elméletben létező hosszú DNS molekulát többféleképpen bontották rövidebb, egymással átfedő szakaszokra, így négyszeres lefedettséggel szintetizáltatták meg a molekulát, ezzel próbálták csökkenteni az adatvesztés lehetőségét. A végén egészen pontosan 153.335 oligonukleotidot terveztek meg, amelyek mindegyike 117 bázispár hosszúságú volt. Érdemes megemlíteni a szerzők megjegyzését, miszerint a teljesen egységes méretű DNS darabok és a homopolimerek teljes hiánya nyilvánvalóvá teszik, hogy a végeredményképpen kapott DNS nem természetes eredetű, így feltételezhetően szándékos tervezés eredménye és információt hordoz.
Azt már szinte közhely, hogy egy DNS molekula alkalmas lenne hosszú távú adattárolásra, hiszen kis helyet foglal és bizonyítottan eláll évezredekig, miközben nem igényel különleges körülményeket. Viszont hátrányai is vannak, például a hosszú, adott szekvenciájú DNS szakaszok szintézise nem megoldott, azaz sehol sem tudnak neked tetszőleges bázissorrendű, egy gigabázis méretű DNS szálat készíteni. Ráadásul a bázissorrend meghatározása nem egyszerű és nem is gyors, de hát ez nyilván nem túl fontos szempont, ha évezredeken át meg akarunk őrizni valamilyen adatot. Nick Goldman és munkatársai (van köztük egy magyar is, Sipos Botond) éppen ezért kicsit másképpen közelítették meg a dolgot: Ismert bázissorrendű rövid DNS szakaszok könnyen és viszonylag olcsón szintetizálhatóak, így eleve ezeket használták föl adattárolásra. A 757 kilobytenyi kiválasztott adatot egy egyszerű kódtábla alapján DNS szekvenciává fordították, amely így nem tartalmazott ismétlődő bázisokat, mivel ezeknél gyakrabban lépnek fel hibák a második generációs szekvenálási eljárások során, így több hibával lennének csak kinyerhetőek az adatok. A csak elméletben létező hosszú DNS molekulát többféleképpen bontották rövidebb, egymással átfedő szakaszokra, így négyszeres lefedettséggel szintetizáltatták meg a molekulát, ezzel próbálták csökkenteni az adatvesztés lehetőségét. A végén egészen pontosan 153.335 oligonukleotidot terveztek meg, amelyek mindegyike 117 bázispár hosszúságú volt. Érdemes megemlíteni a szerzők megjegyzését, miszerint a teljesen egységes méretű DNS darabok és a homopolimerek teljes hiánya nyilvánvalóvá teszik, hogy a végeredményképpen kapott DNS nem természetes eredetű, így feltételezhetően szándékos tervezés eredménye és információt hordoz.
A kész DNS -t liofilizálták (fagyasztva szárították), majd egyszerű postán küldték el az USÁból Németországba, mellőzve minden különleges csomagolási vagy tartósítási eljárást.
A csomagban kapott DNS bázissorrendjét egy második generációs szekvenáló platformmal határozták meg, ezt számítógépen illesztették össze, a nélkül, hogy a fogadó laborban bármit is tudtak volna a kísérlet tervezéséről, vagy a DNS elkészítésének részleteiről. Az eredetileg tárolt öt állományból (Shakespeare összes szonettje .txt állományban, Watson és Crick 1953 -as közleménye a DNS szerkezetéről .pdf formátumban, egy fénykép .jpg formátumban, Martin Luther King egy beszédének részlete .mp3 formátumban és a Huffman kód, amivel az adatokat DNS bázisokká fordították) négyet hibátlanul visszanyertek, az ötödikből két huszonöt bázisnyi szakasz hiányzott csak.
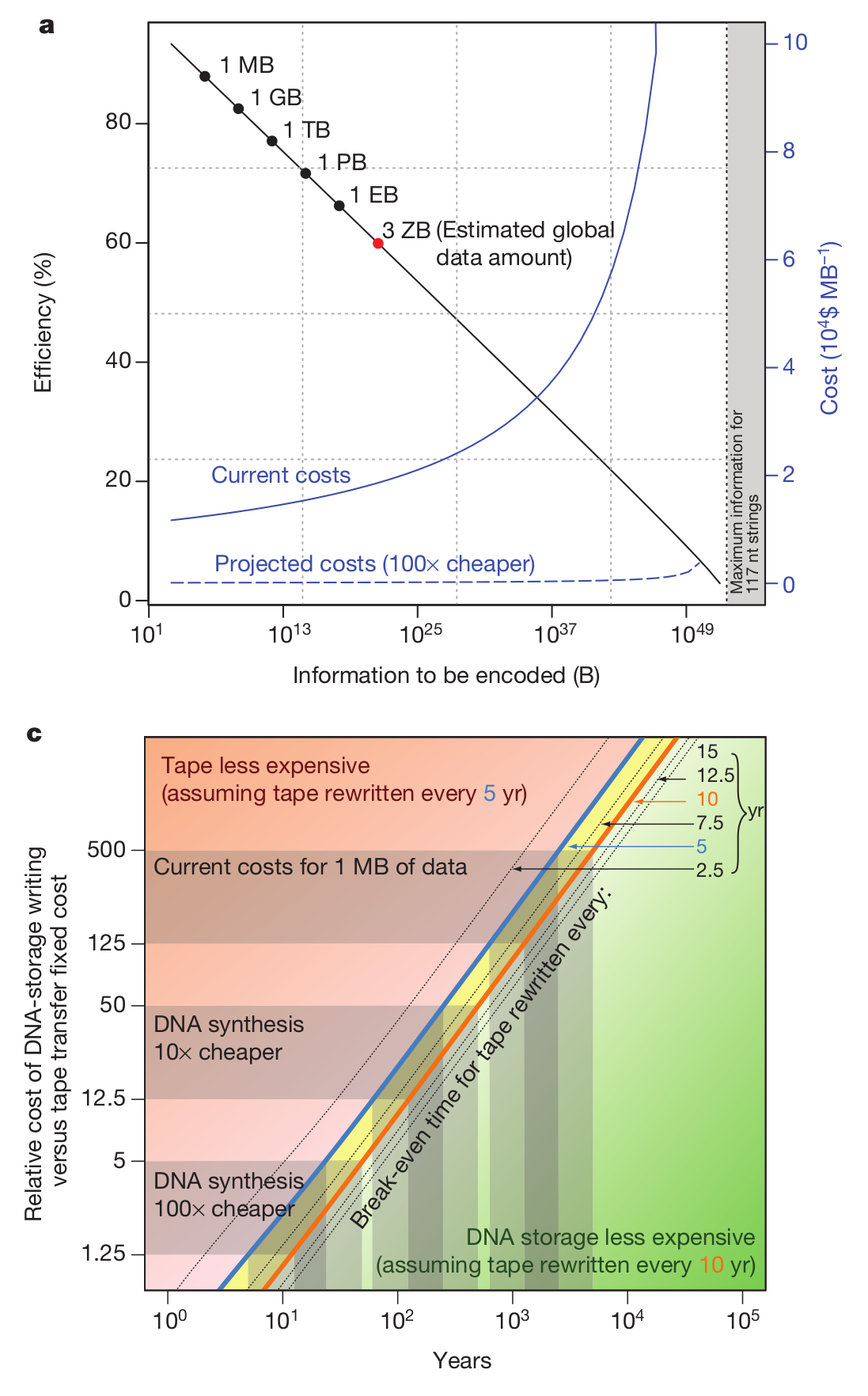 Még egy érdekes összehasonlítást tartalmaz a közlemény, ugyanis ebben a kísérletben egy megabyte méretű adattömeggel dolgoztak, de nyilván felmerül a kérdés, hogy ezzel a technológiával ennél nagyobb adatmennyiségeket mennyiért lehetne tárolni, hiszen a módszer költsége alapvető fontosságú szempont. Meglepő módon nagyobb adatmennyiségeket sem sokkal drágább így tárolni, a második ábrán ez látható, szédítő mennyiségű adattömeg kezelhető a jelenleg rendelkezésünkre álló módszerekkel, bár azért ez még mindig elég drága, legalábbis engem elriasztana a jelenlegi megabyteonkénti 12400 dollár az írásért, és 220 dollár/MB az adat elolvasásáért, bár nyilván ezt jelentősen csökkentené, ha a DNS szintetizálás és/vagy a szekvenálás olcsóbbá válna, vagy akár ha képesek lennénk hosszabb DNS szakaszokat szintetizálni. Viszont bizonyos felhasználási területeken, például kormányzati, vagy történelmi adattárolásra ez a módszer akár már most is olcsóbb lehet, mint a meglévők. Jelenleg a szerzők úgy becsülik, hogy ~600-5000 évnyi időtartamra számítva olcsóbb a módszerük a jelenleg használatos archiválási eljárásoknál, bár ez nyilván függ attól, milyen időközönként írják újra az adathordozókat. Viszont ebben az a sárkányosság, hogy ha az eddigi folyamatok folytatódnak, egy évtized múlva várhatóan százszor olcsóbb lesz a DNS szintézis és szekvenálás, viszont akkor már ötven évnyi időtávra is olcsóbb lesz DNS molekulákban adatot tárolni, mint mágneslemezeken. Szóval könnyen lehet, hogy pár ezer év múlva a régészek nem pergameneket vagy agyagtáblákat böngésznek majd, hanem szekvenálógépekkel dolgoznak.
Még egy érdekes összehasonlítást tartalmaz a közlemény, ugyanis ebben a kísérletben egy megabyte méretű adattömeggel dolgoztak, de nyilván felmerül a kérdés, hogy ezzel a technológiával ennél nagyobb adatmennyiségeket mennyiért lehetne tárolni, hiszen a módszer költsége alapvető fontosságú szempont. Meglepő módon nagyobb adatmennyiségeket sem sokkal drágább így tárolni, a második ábrán ez látható, szédítő mennyiségű adattömeg kezelhető a jelenleg rendelkezésünkre álló módszerekkel, bár azért ez még mindig elég drága, legalábbis engem elriasztana a jelenlegi megabyteonkénti 12400 dollár az írásért, és 220 dollár/MB az adat elolvasásáért, bár nyilván ezt jelentősen csökkentené, ha a DNS szintetizálás és/vagy a szekvenálás olcsóbbá válna, vagy akár ha képesek lennénk hosszabb DNS szakaszokat szintetizálni. Viszont bizonyos felhasználási területeken, például kormányzati, vagy történelmi adattárolásra ez a módszer akár már most is olcsóbb lehet, mint a meglévők. Jelenleg a szerzők úgy becsülik, hogy ~600-5000 évnyi időtartamra számítva olcsóbb a módszerük a jelenleg használatos archiválási eljárásoknál, bár ez nyilván függ attól, milyen időközönként írják újra az adathordozókat. Viszont ebben az a sárkányosság, hogy ha az eddigi folyamatok folytatódnak, egy évtized múlva várhatóan százszor olcsóbb lesz a DNS szintézis és szekvenálás, viszont akkor már ötven évnyi időtávra is olcsóbb lesz DNS molekulákban adatot tárolni, mint mágneslemezeken. Szóval könnyen lehet, hogy pár ezer év múlva a régészek nem pergameneket vagy agyagtáblákat böngésznek majd, hanem szekvenálógépekkel dolgoznak.
Goldman N, Bertone P, Chen S, Dessimoz C, LeProust EM, Sipos B, Birney E. (2013) Towards practical, high-capacity, low-maintenance information storage in synthesized DNA. Nature. 494(7435):77-80
Néhány részletet azért még belevennék a sztoriba: egy trináris kódot készítettek (így a korábban bináris digitális információ már eleve rövidíthető). Persze itt rögtön felmerül, hogy miért pont trináris, hiszen négy bázispár van: valóban négy, de csak hármat használnak aditt pillanatban, pont a nukleotid ismétlődések elkerülésére. Vagyis az egyest attól függően kódolhatja G, C, T vagy A is, hogy az ezt megelőző nukleotida A, T, C vagy G volt.
(lásd még itt is: http://www.economist.com/news/science-and-technology/21570671-archives-could-last-thousands-years-when-stored-dna-instead-magnetic)
Annyi óvatosság még nem árt, hogy nem tudjuk, a liofilizált DNS darabokban mennyi idő alatt alakul majd ki annyi mutáció, hogy azok visszafejtési gondot okozzanak. Ugye elvileg elég egy nukleotida megváltozása, hogy egy komplexebb fájl CRC checksumját megbolondítsa, márpedig a környezeti tényezők közt sok mutagén van (nem véletlenül bonyolult az archaikus DNS visszafejtése).
Ők négyszeres lefedettséggel dolgoztak, tehát egy-egy mutációt még ki lehet küszöbölni, viszont a lefedettség még jócskán növelhető, gondolom nincs elméleti akadálya, hogy tízszeres vagy húszszoros lefedettséggel dolgozzanak, bár nyilván ez megdrágítja a módszert.
Nagyon otletes!
Dolphin: a mutacio talan nem olyan nagy problema, hiszen a szintezisnel nem egyetlen peldany keszult a 117 bazis hosszusagu darabbol, hanem kb egymillio peldany, es visszaolvasasnal is tobb szalat (feluletes olvasasra ugy tunik, hogy kb otvenet) olvasnak el atlagosan mindegyikbol, es marad boven ujraolvasasra valo anyag, ha valahol bizonytalansag van.
Eleve mar a szintezisnel is 1:500 a mutacio eselye a cikk szerint, de a modszer annyira robosztus, hogy ez nem zavarja.
A mutacio veletlenszeruen mas es mashol lesz a kulonbozo molekulakban, igy ismetelt olvasasokbol tobbseg dont alapon eleg sokaig meg lehet allapitani mi volt az eredeti bazis… Ha jol gondolom, ha egy adott pozicioban a bazisok fele mutans, az meg nagy biztonsagu olvasast eredmenyez: 50 %-ban a helyes bazis, 16-16-16 % ban a masik harom bazis lesz jelen.
Vannak hibaturo kodolasok, amivel mar a binaris adatokat lehet hibaturobbe tenni, igy az adat akkor is olvashato, ha adott resze hibas.
en.wikipedia.org/wiki/Error_correction_codes
Átlinkelem a hupra is, szerintem ott is lenne érdeklődő.